- Q.46 Describe the process of setting up a multi-cluster Kubernetes federation.
- Q.47 How do you implement network policies in Kubernetes for security?
- Q.48 What are the differences between Helm v2 and Helm v3?
- Q.49 Discuss the use of Kubernetes Operators for managing databases.
- Q.50 How would you design a highly available and fault-tolerant Kubernetes architecture?
Q.46 Describe the process of setting up a multi-cluster Kubernetes federation.
- Install Federation Control Plane: Deploy the federation control plane components (API server, controller manager) in a host cluster.
- Join Member Clusters: Install the federation agent in each cluster you want to join the federation.
- Define Federated Resources: Create CRDs for the types of resources you want to federate (e.g., Deployments, Services).
- Apply Federation Configuration: Use
kubefedctlto configure placement rules, overrides, and policies for how federated resources should be distributed. - Ongoing Management: Monitor the federation, make adjustments to configuration, and manage member clusters.
Use Cases:
- Geographic distribution: Manage workloads across multiple clusters in different regions for reliability or latency purposes.
- Multi-cloud or hybrid cloud: Federate Kubernetes clusters across multiple cloud providers or on-premises environments.
- Policy enforcement: Apply centralized policies across multiple clusters for security and compliance.
Q.47 How do you implement network policies in Kubernetes for security?
- Kubernetes Network Policies: These are Kubernetes objects (
NetworkPolicykind) that define rules specifying which Pods can communicate with each other based on labels, namespaces, IP ranges, and protocols. - CNI Plugins: You need a network plugin that supports Network Policies (like Calico, Cilium, Weave Net).
Use Cases:
- Pod-level isolation: Restrict access to sensitive Pods on a need-to-know basis.
- Micro-segmentation: Create fine-grained security zones within your cluster.
- Compliance: Enforce network access rules that align with security policies.
Example (Simple NetworkPolicy):
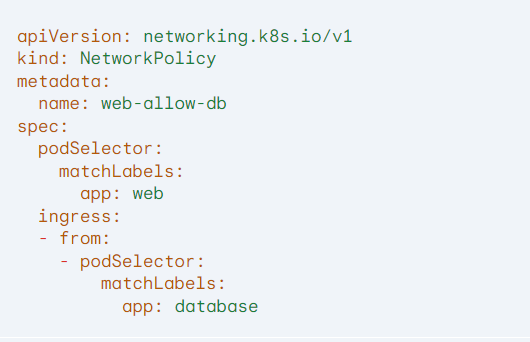
Q.48 What are the differences between Helm v2 and Helm v3?
- Tiller Removal: Helm v2 had a server-side component (Tiller) with security concerns. Helm v3 is client-side only, improving security and simplifying architecture.
- CRDs vs. Secrets: Helm v3 stores release information as CRDs, making them visible in Kubernetes. Helm v2 used Secrets.
- Namespace Scoping: Helm v3 charts are installed into a specific namespace; Helm v2 was cluster-scoped.
- Improved Security: Helm v3 has no Tiller, RBAC integration, and enhanced chart signing support.
Use Cases:
- Upgrading from Helm v2: Understand the changes to migrate releases.
- New deployments: Start with Helm v3 due to its security and simplification advantages.
Q.49 Discuss the use of Kubernetes Operators for managing databases.
Operators excel at managing stateful applications like databases within Kubernetes. They automate complex, administrator-like tasks that go beyond what standard Kubernetes controllers handle:
- Installation and Provisioning: An Operator can deploy a database cluster, configure storage, and set up required resources
- Upgrades and Configuration Changes: Handle schema updates, version upgrades, and complex configuration changes safely.
- Backups and Recovery: Implement backup strategies and facilitate data restoration in case of failures.
- Scaling and Self-Healing: Scale database replicas and respond to failures by automatically provisioning new instances.
Use Cases:
- Simplifying database administration: Reduces the toil of managing databases like PostgreSQL, MySQL, Redis, and MongoDB on Kubernetes.
- Enforcing best practices: Operators encapsulate operational expertise for consistency and reliability.
- Integrating with Kubernetes: Make databases “speak Kubernetes”, aligning with other cloud-native infrastructure components.
Example:
- A PostgreSQL Operator might facilitate cluster creation, automatic backups to cloud storage, and handle failover between primary and standby replicas.
Q.50 How would you design a highly available and fault-tolerant Kubernetes architecture?
- Redundancy at Multiple Levels: Deploy multiple replicas of Pods, spread across worker nodes in different availability zones within a cluster. If one node or zone fails, replicas can failover.
- Self-Healing: Use Deployment or StatefulSet controllers to automatically recreate failed Pods. Include health checks (liveness and readiness probes) to detect issues.
- Cluster-Level HA: Deploy multiple master nodes to avoid a single point of failure in the control plane.
- Distributed Storage: Choose persistent storage systems that replicate data for durability and redundancy.
- Load Balancing: Use Kubernetes Services (and potentially an Ingress Controller) to distribute traffic across healthy replicas of applications.
Use Cases:
- Any production workload where downtime needs to be minimized.
- Mission-critical or customer-facing applications.
Example:
- Multiple Kubernetes worker nodes spread across availability zones.
- A highly-available etcd cluster for the Kubernetes control plane.
- Replicated database backends.
Part 1- Kubernetes Interview Q & A (Q1-Q5)
Part 2- Kubernetes Interview Q & A (Q6-Q10)
Part 3 – Kubernetes Interview Questions & Answers (Q.11 to Q.15)
Part 4 – Kubernetes Interview Questions & Answers (Q.16 to Q.20)
Part 5 – Kubernetes Interview Questions & Answers (Q.21 to Q.25)
Part 6 – Kubernetes Interview Questions & Answers (Q.26 to Q.30)
Part 7 – Kubernetes Interview Questions & Answers (Q.31 to Q.35)
Part 8 – Kubernetes Interview Questions & Answers (Q.36 to Q.40)
Part 9 – Kubernetes Interview Questions & Answers (Q.41 to Q.45)
Hope you find this post helpful.
Telegram: https://t.me/LearnDevOpsForFree
Twitter: https://twitter.com/techyoutbe
Youtube: https://www.youtube.com/@T3Ptech